Fuzzing Irssi
Posted by Joseph Bisch on May 12th 2017
Hello fellow Irssi users and people interested in learning about fuzzing,
There have been recent efforts within the Irssi and open source security communities to make Irssi more secure through the use of fuzzing. For example the security bugs revealed in the first Irssi security advisory of 2017 were found by fuzzing. In this blog post, we will cover an introduction to fuzzing, how to fuzz Irssi, and a look at a couple of actual bugs found in past versions of Irssi.
Intro to Fuzzing
At its most basic level, fuzzing can be thought of as generating random input and feeding it to a program. The program is monitored for crashes or assertion failures. Some of these crashes or assertion failures can be a result of bugs with security implications. An interesting use of assertions in conjunction with fuzz testing is testing protocols for correctness. If you have two libraries that are supposed to both implement the same protocol, you can repeatedly generate random data and feed that same data to corresponding functions in each library and assert that the results must be the same.
Fuzzing is typically done by some program that is responsible for generating the input and then calling the program that is being tested with that input. This is done repeatedly until there is a crash recorded, or some fuzzers will keep running and collect multiple crashes. While these fuzzers may be unaware of how the input affects program execution, there are other fuzzers that make use of something called instrumentation that allows the fuzzer to determine which inputs result in new program coverage. The idea is that there may be bugs that are present only in a certain part of the program and they would otherwise be hard to find if not for the fuzzer trying to find new coverage. Examples of fuzzers that make use of coverage are AFL and libfuzzer, though AFL also has a "dumb fuzzer" mode that behaves like a traditional fuzzer without instrumentation. Libfuzzer is actually a fuzzing library so it doesn't run your program repeatedly, but rather actually links into your code to form a "fuzz target" that will repeatedly call function(s) that you want to test. This is known as "in-process fuzzing".
Fuzzing Irssi
In this section we will look at a patch written by dx that allows for fuzzing of Irssi using AFL. It does so by moving the network communciation onto stdin and stdout. The fuzzer essentially acts as an IRC server that Irssi connects to and accepts data from. Once the fuzzer finishes sending data, Irssi will terminate to allow the fuzzer to start again with new data.
We will also look at a particular CVE found via this methodology, namely CVE-2017-5193.
Here is the patch that can be applied to your Irssi source tree in order to allow fuzzing of Irssi with AFL: patch.
The patch causes Irssi to "connect" to stdin. It also does some other stuff, like preventing the reading from and saving to of the user's config files, so that we start with a default Irssi config every program execution.
The following commands will clone a fresh copy of Irssi and apply the above
patch (named fuzz.diff) to your copy of Irssi. Note that the patch doesn't
apply to git master anymore, so you'll either need to correct the part in
src/fe-text/irssi.c that fails to apply, or checkout any commit prior to
70f9db3cbdc0a3c6b622e64edbd504592f921892 before applying the patch. Note that
this includes any Irssi release at the time of this writing (1.0.2 or earlier).
git clone https://github.com/irssi/irssi.git irssi-fuzz
cd irssi-fuzz
patch -p1 < fuzz.diff
The following commands will configure and build Irssi. If you already ran autogen.sh on your copy of the Irssi source, you can replace ./autogen.sh with ./configure.
CC=/path/to/afl/afl-clang-fast CXX=/path/to/afl/afl-clang-fast++ ./autogen.sh --disable-shared
make
Now the irssi binary is located at src/fe-text/irssi.
Run AFL using the following commands:
mkdir afl
cd afl
mkdir in
echo 'initial testcase' > in/initial
cp ../src/fe-fuzz/tokens.dict .
/path/to/afl/afl-fuzz -i in -o out -x tokens.dict -- ../src/fe-text/irssi
The in directory is the directory of initial inputs each containing some
sequence of bytes that will be the initial inputs fed to the program being
tested (Irssi in our case). The inputs are ideally meaningful to the program
being tested or maybe were gathered from a previous fuzzing session using AFL or
some other fuzzer. In this demonstration, I just have a single input with the
string 'initial testcase\n'. The out directory is where the crashes and hangs
and other interesting data will be stored. The tokens.dict file is a
collection of meaningful tokens that will be utilized as part of the fuzzing
process to find new code paths quicker. The dictionary tokens will be inserted
into the input and also used to overwrite parts of the input. The -- separates
the afl-fuzz commands from the binary we are fuzzing and the flags we will be
giving it. Note that AFL also supports fuzzing a program that reads from a file
passed as an argument. So if we instead modified Irssi to read from a file, we
could instead have -- ./src/fe-text/irssi @@ and AFL would feed Irssi a file
as argv[1]. But in this case there is no @@ as part of the command, so AFL
feeds data to Irssi on stdin.
Now that you ran afl-fuzz, you will see the AFL UI appear in your terminal
that will allow you to monitor the fuzzing progress. You should start to see the
number of paths discovered (the second number from the top on the right side of
the interface as of the time of writing this post) increasing. AFL should
quickly display a message saying that it is odd, if no paths are found. In that
case, you should check to see if the program you are fuzzing is actually reading
data from stdin.
Here is an image showing the AFL UI that displays:
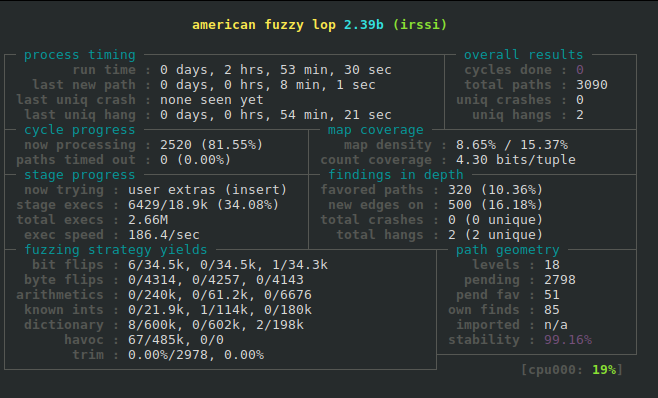
As you can see no crashes have been found so far during that fuzzing session. AFL has found a total of 3090 inputs that cause new paths to be taken and currently AFL is in the process of fuzzing the 2520th of those inputs, which is 81.55% of the way through the 3090 found so far. Of course that percentage can go down as new paths are discovered.
Here is an example of a crash discovered while fuzzing a contrived program. Notice the "odd, check syntax!" warning that is displayed. Normally that is an indication that something is wrong, but in this case the program is just a simple program that AFL can't find any additional paths through, hence the warning.
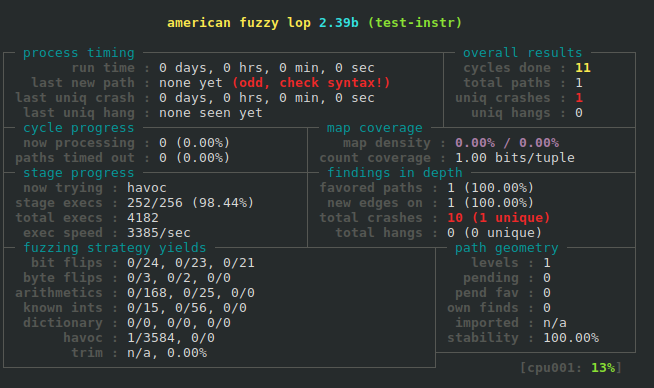
Now we can go to afl/out/crashes in our program's source tree and find crashes
with filenames like out/crashes/id:000000,sig:06,src:000000,op:havoc,rep:32,
indicating a unique id for the crash, the signal with which the program crashed,
the previous input that this one is based on, and the operation performed on the
previous input. You should then be able to then do the following to reproduce
the crash and hopefully get some information about the crash: cat file | program, where file is the file in out/crashes/ and program is the program
you were testing.
CVE-2017-5193
CVE-2017-5193 was a NULL pointer dereference in the nickcmp function that I found using AFL and the above patch. As you can see in the commit that fixed the issue, the fix is just a matter of ensuring nick is non-NULL. The exploit allowed the server to crash Irssi. Since the NULL pointer dereference results in a segfault, this kind of issue is detectable just with Irssi, the above patch, and AFL.
If you want to reproduce CVE-2017-5193, you will want to follow the above instructions and be prepared to wait many many hours. Also, you should make sure that you have built Irssi <= 0.8.20, since 0.8.21 fixes CVE-2017-5193. There are some things you can do to speed up fuzzing in the case of this particular demo, such as setting the initial testcase to be something close to the reproducer and using a limited dictionary that has just the tokens that are part of the reproducer. Here is how you may do so:
echo $'001\nprivmsg\nprivmsg 0 ' > in/initial
echo '"\x01ACTION"' > tokens.dict
I want to stress that we are using a limited dictionary and using this particular initial testcase in an attempt to re-discover a particular bug. It would normally not be beneficial to use a dictionary with a single token instead of a more comprehensive collection of tokens.
For those of you that don't want to wait or that want to ensure that what you've found is actually CVE-2017-5193, here is the minimized trigger:
echo $'001\nprivmsg\nprivmsg 0 :\x01ACTION ' | nc -l -p 6667
Since that command results in a server listening on port 6667 locally, you can
just start a vulnerable instance of Irssi and then enter: /connect localhost
to trigger the crash.
What can I do to help with fuzzing Irssi?...
...is a question you may be asking yourself after having read this post. I hope you learned something from this post either way, but we do have ways you can help if you are interested in doing so.
We could use more code coverage. Of course we can't find bugs in code that we're not able to reach. The above patch was written as a quick hack to get fuzzing of Irssi working and it may be possible to write a patch that results in better coverage. For example, the patch forces a default Irssi config instead of reading the config from the filesystem. So if a bug is only triggerable with a particular configuration or layout, it will be missed when fuzzing with the patch in its current state.
There are also other approaches to fuzzing besides using this patch with AFL. While it wasn't the subject of this blog post, we have a fuzzing frontend that is libfuzzer based. So that is something else you can take a look at improving. There may be another blog post soon that takes a look at the fuzzing frontend.
As always, #irssi on irc.libera.chat is a great place to discuss Irssi.
And we would like to hear about any bugs you find, whether by fuzzing or other methods. You can report non-security bugs via the Irssi GitHub repo. Security bugs can be reported to Irssi staff. Staff can be reached at staff@irssi.org.
Thanks to Softdroid for a Russian translation of this article.